Imanic: A Year of AI-Directed Engineering
Solo-built edtech platform for homeschool families. Eleven months of evenings and weekends. A case study in directing AI to build production-grade software.

What I Built
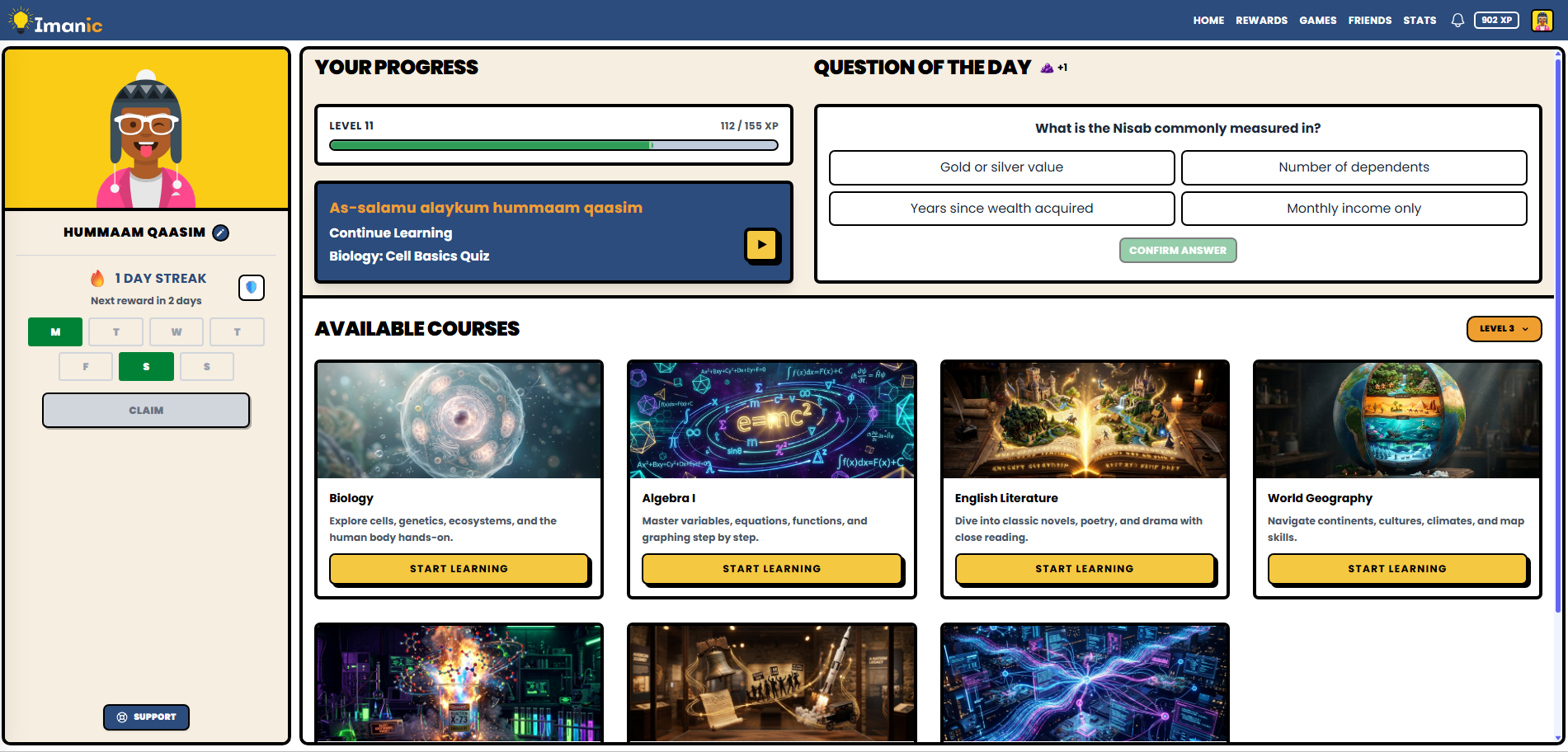
Imanic is a gamified learning platform for homeschool families. It includes courses, lessons, quizzes, signed video playback, a full XP and badge economy, Stripe subscription billing, and parent-child accounts where parents can actually see how their kids are doing. Launching mid-July 2026.
This isn't some simple little app. The backend is a NestJS API (strict TypeScript) running on its own server, handling authentication, authorization, billing, content delivery, the reward engine, and a daily quiz system that just keeps going. The frontend is a separate Next.js 15 / React 19 application. Data lives in PostgreSQL through Directus. Stripe handles payments, Mux serves the signed videos, and Sentry watches for trouble. The whole thing runs on Render behind Cloudflare with a clean Git-backed workflow that keeps development and production completely separate.
I built the entire thing solo over eleven months, evenings and weekends from February through December 2025, while working full-time as a founding analytics engineer. Yes, sleep was optional.
Why I'm Building This
I hated school. Not learning, I loved learning. Just the way it was delivered. Everything was built for a classroom, not a student.
What's different now is that we finally have the data to do personalization properly. Every click, every skipped lesson, every quiz retry, every moment a student quietly gives up. The problem is that nobody is doing anything useful with it. Collecting that behavior is easy. The hard part is turning it into something useful, modeling it, transforming it, and feeding it back into the experience so the next lesson actually fits the kid sitting in front of it. That's a data problem, and it's one I genuinely want to solve.
How I Built It
I wanted to treat Claude Code like a very talented but slightly chaotic junior developer, not a magic button.
I did the architecture. I wrote the specs. Claude wrote a lot of the code, but only after I told it exactly what to build and why. Every major feature started with a proper design document. I had written specs for the auth flows, billing system, reward economy, activity pipeline, and security model before any production code was generated.
When I wasn't sure about the best approach, I'd ask Claude for options, think through the trade-offs myself, and make the final call. The big architectural decisions were mine. Many of the smaller ones were collaborative. But every deployment decision? That was on me. No surprises if I could help it.
The pattern across eleven months was simple: spec, draft, review, ship. Claude Code would draft an implementation in a feature branch on the dev workspace. I'd read the diff, push back on anything that didn't feel right, run the tests, and iterate. When it was solid, I'd open a PR, review the full change set, and merge to main. The deploy went out through Render's build pipeline. The AI never touched production directly.
The git history tells the real story. Incremental, well-scoped commits with conventional formatting. No giant dumps of code. Feature branches, pull requests, and real code review. The same workflow you'd run with a human teammate, except the teammate is an LLM and the entire review burden sits on you.
The Product
Authentication and authorization. Session-based auth with email verification and Google OAuth. A clean parent-child model where one parent owns multiple student accounts. Authorization guards make sure a parent can only access their own children's data. I even wrote a test that tries to break that boundary on purpose, just to prove it holds.
Billing. Stripe subscriptions with webhook-driven state management. Seat-based plans where parents can add or remove child accounts. Subscription state lives in its own table as a downstream projection of Stripe's source of truth. The downgrade path, deciding which kids to suspend and in what order, has proper tests.
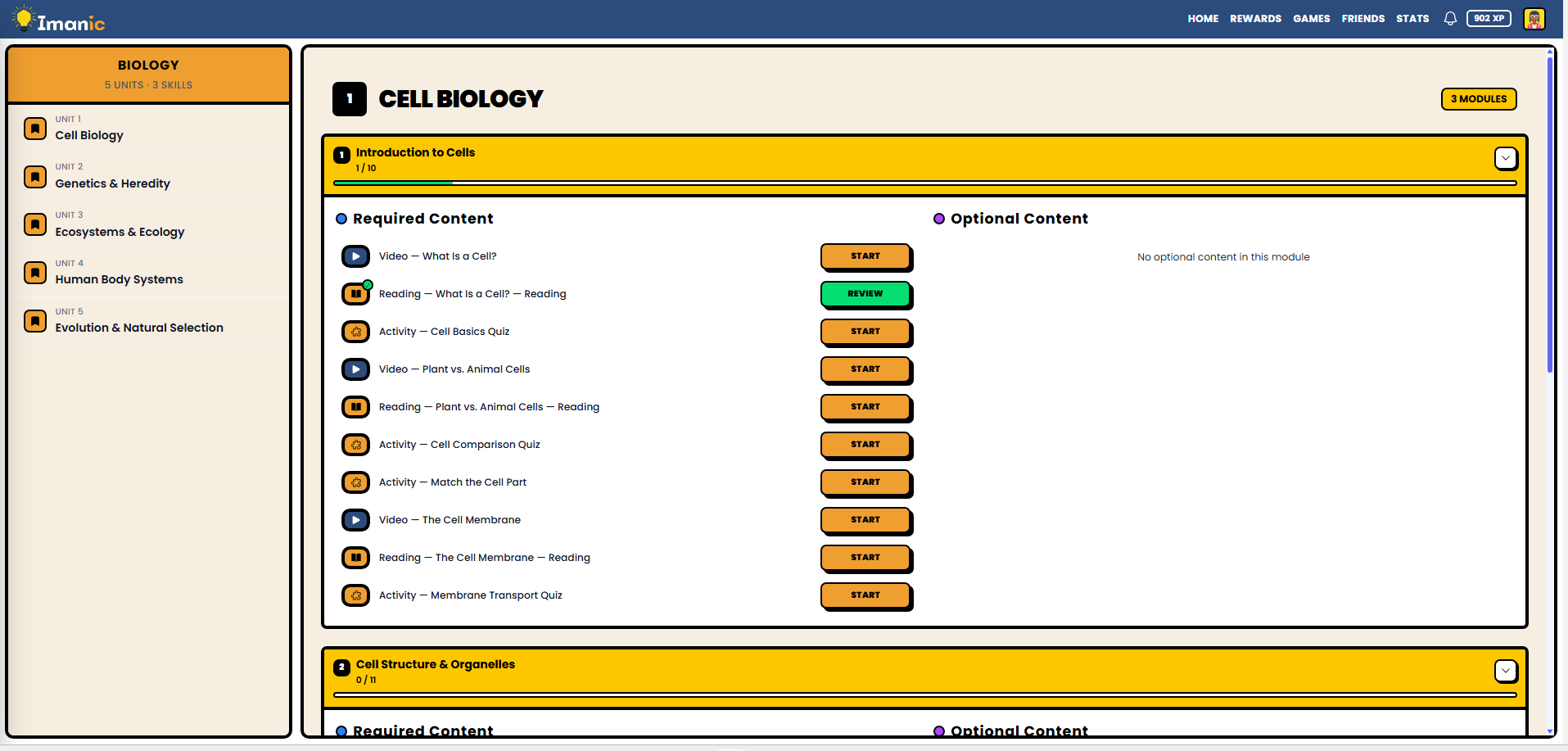
Content and gamification. A full course hierarchy with courses, sections, modules, lessons, and activities. A learning events coordinator routes every completion through XP grants, gem rewards, badge checks, and streak tracking in a strict deterministic sequence. Idempotency is enforced at the database level so duplicate submissions are structurally impossible.
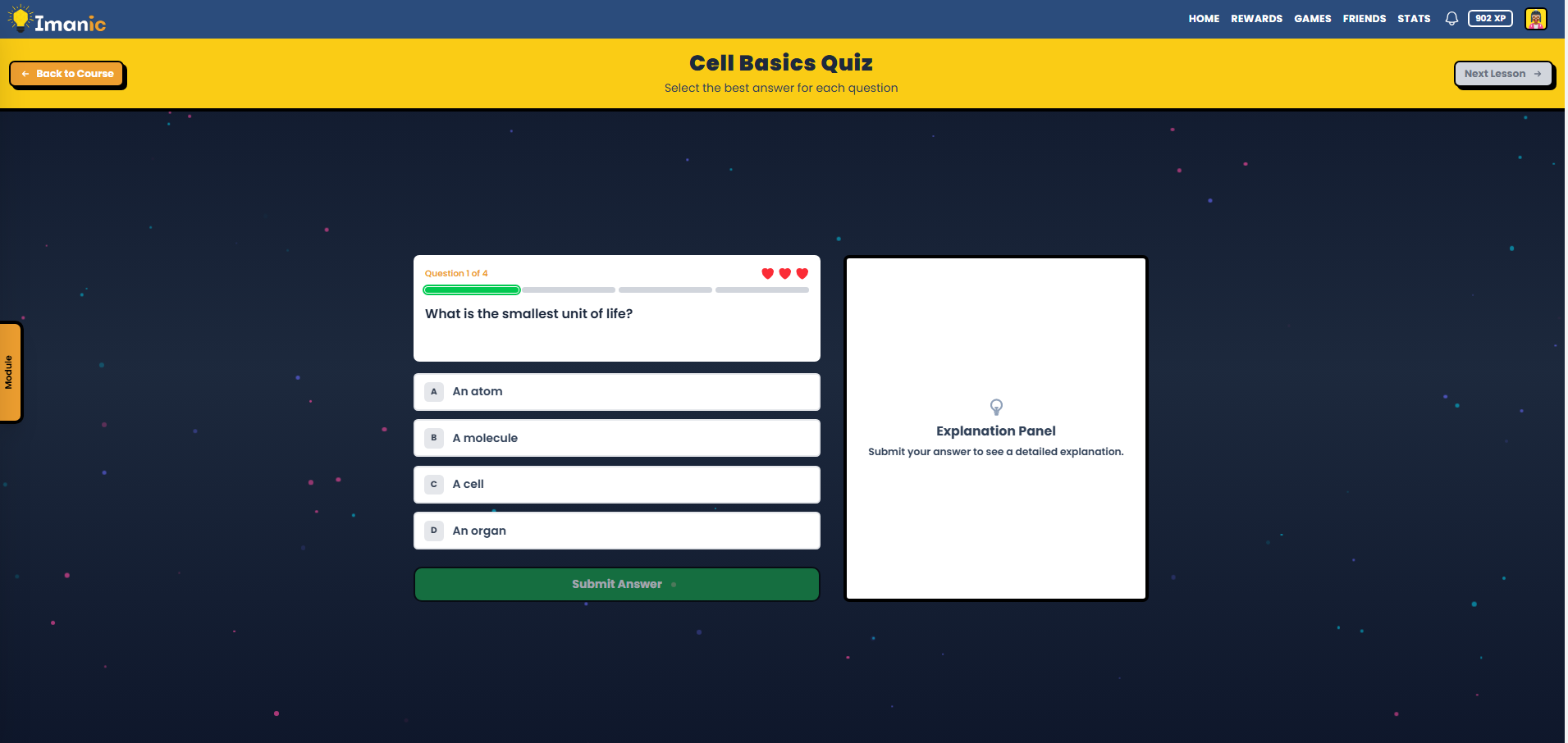
Daily quiz. A scheduled job creates a fresh quiz every day. It uses semantic similarity to avoid repeating questions, with a second check for near-duplicates the first pass might miss. This engine is on its third architecture. The first two taught me a lot about the difference between surface-level and meaning-level deduplication.
Security. Rate limiting, CSRF protection, security headers, and careful PII redaction in error logs. There's a full security audit documented in the repo. It's not enterprise-grade, but it's solid for a consumer SaaS at launch.
What Production Taught Me
The biggest lesson came from the Stripe integration. Three race conditions appeared as soon as real webhook traffic hit the live system.
One webhook arrived missing fields. Another time the customer object wasn't there when the checkout event fired. And a subscription update sometimes arrived before the original create event had finished writing. Three different failure modes, three different fixes. Claude Code's original implementation followed the textbook perfectly for the common case. The AI is great at the happy path. The engineer's job is spotting the uncommon cases that will actually hurt you.
Ten days later I applied the same lesson before it became a problem. The XP reward system had been running for months without database-level idempotency. The Stripe fires made it obvious the same class of bug was sitting quietly in another part of the code. I had Claude Code add the proper composite-unique constraints and write a backfill script before it ever became an issue. That kind of pattern recognition, seeing a failure in one place and fixing it elsewhere before it breaks, is something the AI still can't do on its own.
What I Won't Overclaim
The test suite is focused, not exhaustive. Auth, billing, activity completion, and rewards are well covered. The daily quiz deduplication engine has been running reliably for months, but it doesn't have unit tests on the similarity logic yet. That's a known gap.
The database schema is managed through the CMS layer rather than code-driven migrations. It worked fine for a solo project, but it wouldn't scale to a team.
Rate limiting is appropriate for launch scale. It's not distributed.
I used the AI for implementation decisions, not just code. When I didn't know the best pattern for something, I asked, evaluated the options, and decided. I'm not pretending I had every answer before I prompted. What I did have was the judgment to review what came back, the discipline to write specs first, and the willingness to throw away output that didn't hold up.
What I'd Do Differently
I'd write the database schema in code from day one. Managing it through the CMS layer was fast, but it left me with no migration history and no clear record of changes. On a team, that would be painful.
I'd invest in deduplication tests earlier. The daily quiz engine went through three full architectures, and I mostly validated it by watching the output instead of writing proper assertions. That works when you're the only person looking, but it's not a habit I'd repeat.
I'd also add end-to-end tests on the billing flows much sooner. The Stripe webhook issues were caught quickly because I was watching production closely, but "the developer is watching" is not a real monitoring strategy. Automated tests on the critical billing paths would have caught those race conditions in staging instead of live.
The Stack
NestJS 11 with strict TypeScript on Node 22, Next.js 15 and React 19, Directus on PostgreSQL, Redis for sessions, Stripe for billing, Mux for signed video, Sentry for observability, Render and Cloudflare for infrastructure, and Claude Code for AI-directed implementation. Everything runs with a Git-backed PR workflow and clear separation between dev and production workspaces. Solo build, eleven months.