déjano
A novelty layer for LLM apps that stops a daily generator from repeating itself using semantic dedup.
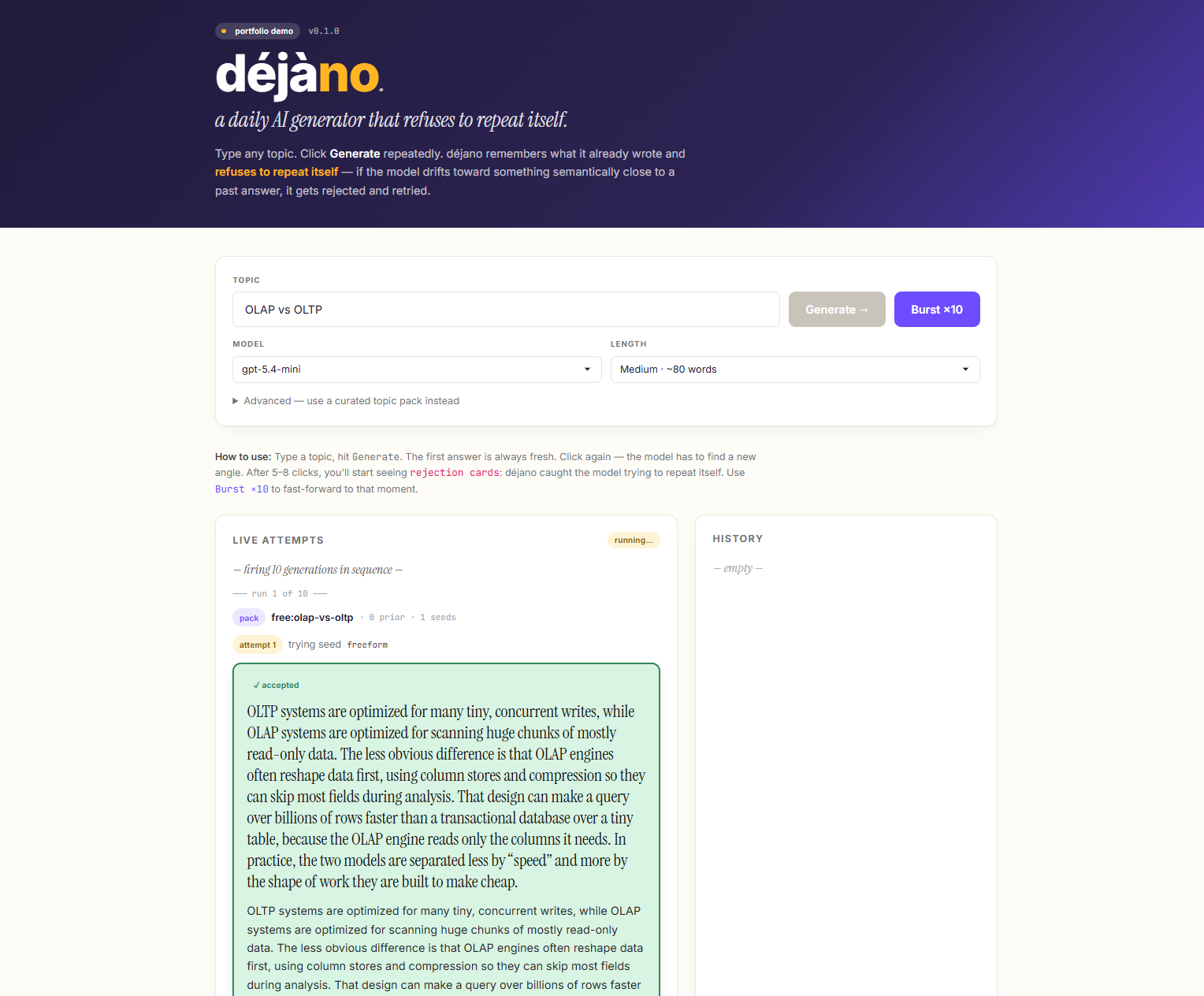
LLMs are good at producing one good answer. They're bad at producing thirty different ones in a row. Ask a model for a daily trivia question and within a week half of them are about the pyramids. It has favorites, and it converges on them. déjano is a layer that sits between your app and the LLM and makes sure that doesn't happen.
How it works
Three checks, cheapest first. Every candidate gets compared against history using Jaccard token overlap, which is free and doesn't need an API call. Survivors get embedded, and if the cosine similarity to any prior item crosses the threshold, the candidate is rejected. This catches the paraphrases that the token test misses. When something gets rejected, the model is asked again with the rejected attempt added to a do-not-repeat list. The generator gets harder to repeat itself over time, not easier.
Key decisions
History and embeddings live in a local better-sqlite3 store, with vectors stored as Float32 BLOBs. The web layer is Hono, streaming each generation attempt over Server-Sent Events so you can see rejections happening live as they fire. The provider interfaces (LLM, embedding, and storage) are kept small and swappable so you can plug in Anthropic, Postgres, or local models without touching the dedup logic.
Built for any product where the same kind of thing needs to be generated day after day: daily quiz questions, journal prompts, standup icebreakers, anything where a repeat would be embarrassing if a user noticed. MIT licensed.